Сайт о сжатии >> ARCTEST
Сравнительные тесты Альтернативные тесты
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

|
 |
||
|
[an error occurred while processing this directive]
|
||
Сжатие информации
Пусть у нас имеется файл размером 1 (один) мегабайт. Нам необходимо получить из него файл меньшего размера. Ничего сложного - запускаем архиватор, к примеру, WinZip, и получаем в результате, допустим, файл размером 600 килобайт. Куда же делись остальные 424 килобайта? Ответ на этот вопрос очень непрост, однако мы попытаемся его найти. Итак, начнем, как всегда, сначала.
Рассмотрение методов сжатия информации мы начнем с простых универсальных алгоритмов и лишь после них перейдем к более специализированным методам сжатия графики, звука и видео.
Сжатие информации является одним из способов ее кодирования. Вообще коды делятся на три большие группы - коды сжатия (эффективные коды), помехоустойчивые коды и криптографические коды. Коды, предназначенные для сжатия информации, делятся, в свою очередь, на коды без потерь и коды с потерями. Кодирование без потерь подразумевает абсолютно точное восстановление данных после декодирования и может применяться для сжатия любой информации. Кодирование с потерями имеет обычно гораздо более высокую степень сжатия, чем кодирование без потерь, но допускает некоторые отклонения декодированных данных от исходных.
Сжатие с потерями применяется в основном для графики (JPEG), звука (MP3), видео (MPEG), то есть там, где мелкие отклонения от оригинала незаметны или несущественны, а степень сжатия в силу огромных размеров файлов очень важна. Сжатие без потерь применяется во всех остальных случаях - для текстов, исполняемых файлов, высококачественного звука и графики и т.д. и т.п.
Основные понятия
Существует множество определений термина "информация" - от самого общего, философского (информация есть отражение реального мира), до очень узкого (информация есть все сведения, являющиеся объектом хранения, передачи и преобразования). Однако, если вдуматься в суть этих определений, мы быстро поймем, что первое из них совершенно нефункционально, а второе в своей основе рекурсивно - ведь если мы попытаемся определить слово "сведения", мы с неизбежностью возвратимся к понятию "информация". Поэтому для рассмотрения процессов обработки информации пользуются определением, которое по степени обобщения лежит где-то между предыдущими двумя. Итак, под информацией мы будем понимать то, что уменьшает степень нашего незнания относительно того или иного объекта или явления.
Теоретическими аспектами обработки и передачи информации занимается так называемая теория информации, называемая также информатикой. (Правда, в школьной программе этим словом назван некий странный предмет, не имеющий ничего общего ни с теорией информации, ни с информацией вообще.)
Информацию, как и всякую другую реально существующую величину, можно измерить, то есть выразить ее объем в некоторых единицах измерения. В теории информации существует три качественно разных подхода к измерению количества информации: подход структурный, в рамках которого количество информации определяется на основе количества элементов в данном массиве информации, подход статистический, который, кроме простого подсчета элементов массива, учитывает еще и вероятности их появления, и подход семантический, который определяет количество информации как степень ее полезности и целесообразности. Итак, все три подхода предлагают методы, на основе которых можно с математической точностью подсчитать количество информации, содержащееся в каком-либо массиве, и, что самое удивительное, во всех трех случаях получить совершенно разные ответы. Более того, при статистическом методе измерения количества информации, содержащейся в данном файле, мы можем получить нецелое число бит, а при семантическом - даже отрицательное их количество!
Рассмотрим, чем отличаются друг от друга вышеупомянутые подходы к измерению количества информации.
При структурном подходе мы просто считаем, что файл, занимающий 1 Кб, содержит в себе также ровно 1 Кб информации. Согласитесь, очень логично!
При семантическом подходе количество информации оценивается по тому эффекту, который она производит на некоторый объект. Допустим, что некоторая информация должна помочь нам в достижении некоторой цели. Пусть вероятность достижения данной цели без получения данной информации составляет p1, а с получением данной информации - p2. Тогда количество этой информации равно: I = log p2/p1 бит.
Очевидно, структурный подход никак не может помочь нам при сжатии информации. Семантический как будто может, но возникает масса неясностей - как именно оценивать влияние информации на ее конечного потребителя - ведь архиватор, в общем случае, ничего не "знает" о столь тонких материях. Итак, выручить нас может только статистический подход к измерению количества информации.
Итак, пусть из какого-либо источника поступает информация в дискретной
форме, в виде последовательности байт. Если бы эти байты генерировались бы
неким совершенно случайным образом, вероятность появления какого-либо
конкретного значения (например, 6Eh) составила бы ровно 1/256. Но в
большинстве реальных источников информации вероятность появления разных
значений также различна. В самом деле, когда мы пишем текст в редакторе, у
нас есть все основания полагать, что буква "а" встречается чаще, чем буква
"ц". На основе информации о вероятностях появления тех или иных символов
можно вычислить энтропию текста. В статистической теории информации,
созданной Клодом Шенноном в 1948 году, энтропия определяется как
количество информации на один символ. Формулу для расчета энтропии
приводить здесь не будем - за последние пятьдесят лет она была
опубликована такое число раз, что желающие отыщут ее без всякого труда.
Однако некоторые закономерности, присущие информационной энтропии, мы
опишем.
Для дальнейших рассуждений будет удобно представить наш исходный файл с текстом как источник символов, которые по одному появляются на его выходе. Мы не знаем заранее, какой символ будет следующим, но мы знаем, что с вероятностью p1 появится буква "а", с вероятностью p2 -буква "б" и т.д.
В простейшем случае мы будем считать все символы текста независимыми друг от друга, т.е. вероятность появления очередного символа не зависит от значения предыдущего символа. Конечно, для осмысленного текста это не так, но сейчас мы рассматриваем очень упрощенную ситуацию. В этом случае справедливо утверждение "символ несет в себе тем больше информации, чем меньше вероятность его появления".
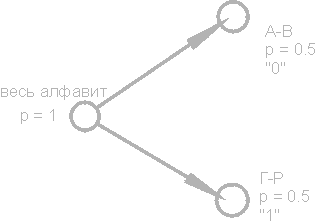
Давайте представим себе текст, алфавит которого состоит всего из 16 букв: А, Б, В, Г, Д, Е, Ж, З, И, К, Л, М, Н, О, П, Р. Каждый из этих знаков можно закодировать с помощью всего 4 бит: от 0000 до 1111. Теперь представим себе, что вероятности появления этих символов распределены следующим образом:
| А | Б | В | Г | Д | Е | Ж | З | И | К | Л | М | Н | О | П | Р |
| 0.2 | 0.15 | 0.15 | 0.1 | 0.08 | 0.08 | 0.06 | 0.04 | 0.03 | 0.022 | 0.018 | 0.016 | 0.014 | 0.014 | 0.013 | 0.013 |
Сумма этих вероятностей составляет, естественно, единицу. Разобьем эти символы на две группы таким образом, чтобы суммарная вероятность символов каждой группы составляла ~0.5 (рис. 1 ). В нашем примере это будут группы символов А-В и Г-Р. Кружочки на рисунке, обозначающие группы символов, называются вершинами или узлами (nodes), а сама конструкция из этих узлов - двоичным деревом (B-tree) . Присвоим каждому узлу свой код, обозначив один узел цифрой 0, а другой - цифрой 1.
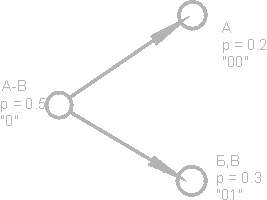
Снова разобьем первую группу (А-В) на две подгруппы таким образом, чтобы их суммарные вероятности были как можно ближе друг к другу. Добавим к коду первой подгруппы цифру 0, а к коду второй - цифру 1.
Будем повторять эту операцию до тех пор, пока на каждой вершине нашего "дерева" не останется по одному символу. Полное дерево для нашего алфавита будет иметь 31 узел.
Коды символов (крайние правые узлы дерева) имеют коды неодинаковой длины. Так, буква А, имеющая для нашего воображаемого текста вероятность p=0.2, кодируется всего двумя битами, а буква Р (на рисунке не показана), имеющая вероятность p=0.013, кодируется аж шестибитовой комбинацией.
Итак, принцип очевиден - часто встречающиеся символы кодируются меньшим числом бит, редко встречающиеся - большим. В результате среднестатистическое количество бит на символ будет равно
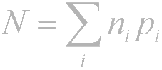 где ni - количество бит, кодирующих i-й символ, pi - вероятность
появления i-го символа.
где ni - количество бит, кодирующих i-й символ, pi - вероятность
появления i-го символа.
Кстати, рассмотренный выше способ кодирования носит название кода Шеннона-Фэно. Очень близок к нему код Хаффмана. Но и код Шеннона-Фэно, и код Хаффмана имеют один существенный недостаток - они никак не учитывают взаимосвязей между символами, которые присутствуют практически в любом тексте. Например, если в тексте на английском языке нам встречается буква q, то мы с уверенностью сможем сказать, что после нее будет идти буква u.
Примеров взаимных связей, или, говоря техническим языком, корреляций, можно привести множество. Для кодирования данных с корреляционными зависимостями предназначен код LZW.
LZW
LZW-код (Lempel-Ziv & Welch) является на сегодняшний день одним из самых распространенных кодов сжатия без потерь. Именно с помощью LZW-кода осуществляется сжатие в таких графических форматах, как TIFF и GIF, с помощью модификаций LZW осуществляют свои функции очень многие универсальные архиваторы. К сожалению, детально описать его работу простым языком не представляется возможным. В документации его работа описана при помощи языка C, что для большинства наших читателей будет, пожалуй, тяжеловато. Скажем только, что работа алгоритма основана на поиске во входном файле повторяющихся последовательностей символов, которые кодируются комбинациями длиной от 8 до 12 бит. Таким образом, наибольшую эффективность данный алгоритм имеет на текстовых файлах и на графических файлах, в которых имеются большие одноцветные участки или повторяющиеся последовательности пикселов. Реализация алгоритма LZW жестко зафиксирована международным стандартом и Американским Национальным институтом стандартов (ANSI), однако существуют достаточно интересные его модификации, которые дают больший коэффициент сжатия некоторых специфичных типах файлов - например, на исходных текстах программ.
Отсутствие потерь информации при LZW-кодировании обусловило широкое распространение основанного на нем формата TIFF. Этот формат не накладывает каких-либо ограничений на размер и глубину цвета изображения и широко распространен, например, в полиграфии. Другой основанный на LZW формат - GIF - более примитивен - он позволяет хранить изображения с глубиной цвета не более 8 бит/пиксел. В начале GIF - файла находится палитра - таблица, устанавливающая соответствие между индексом цвета - числом в диапазоне от 0 до 255 и истинным, 24-битным значением цвета.
Таким образом, этот формат можно назвать форматом без потерь лишь в том смысле, что все потери информации происходят до LZW-кодирования - при преобразовании исходной картинки в 8-битную с индексированной палитрой.
Несомненным достоинством этого формата является возможность хранить в одном файле последовательности изображений, образующих примитивную анимацию. Именно благодаря этой особенности он нашел широкое применение в Internet.
Как можно улучшить степень сжатия при использовании формата GIF?
Просмотрите палитру вашего рисунка с помощью графического редактора - например, с помощью Corel Photo Paint. Вы можете обнаружить в ней очень близкие цвета. Если заменить пикселы одного из этих цветов на пикселы другого цвета, то вы можете получить заметное уменьшение файла, правда, за счет некоторой потери цветовой глубины.
В GIF-анимациях для каждой картинки может быть сформирована отдельная палитра. Если ее нет, данная картинка будет выводиться в глобальной палитре - той самой, что расположена в начале файла. Поэтому вы можете существенно уменьшить размер выходного файла, если все изображения в анимации будут иметь общую палитру - ведь каждая палитра имеет размер 256*3=768 байт.
Еще одна хитрая особенность GIF заключается в том, что в анимационных кадрах можно хранить изображение не полного размера, а лишь тот участок, который меняется по сравнению с предыдущим кадром. Допустим, вы хотите изобразить самолетик, пролетающий над домом. Для реализации такой анимации вам достаточно в каждом последующем кадре изображать только самолетик, сдвинутый относительно предыдущего кадра, с указанием его координат.
Естественно, самолетик из второго кадра должен полностью перекрывать аналогичный объект из первого кадра. Такой подход позволяет уменьшить размер файла в несколько раз!
Изготовить анимацию для Internet можно еще одним способом. Нужно подготовить все изображения в формате JPEG и изготовить Java-скрипт, выводящий их в определенной последовательности. При более изощренном владении Явой можно реализовать и описанный выше "кусочный" подход. С учетом того, что JPEG дает несравненно большее сжатие, чем GIF, такая технология может оказаться очень эффективной. А если представить себе все спецэффекты, которые можно реализовать с помощью Java... Но мы несколько отклонились от темы. Итак, раз уж речь зашла о JPEG, обсудим подробнее этот замечательный графический формат.
JPEG
Алгоритм JPEG был разработан группой фирм под названием Joint Photographic Experts Group. Целью проекта являлось создание высокоэффективного стандарта сжатия как черно-белых, так и цветных изображений, эта цель и была достигнута разработчиками. В настоящее время JPEG находит широчайшее применение там, где требуется высокая степень сжатия - например, в Internet.
В отличие от LZW-алгоритма JPEG-кодирование является кодированием с потерями. Сам алгоритм кодирования базируется на очень сложной математике, но в общих чертах его можно описать так: изображение разбивается на квадраты 8*8 пикселов, а затем каждый квадрат преобразуется в последовательную цепочку из 64 пикселов. Далее каждая такая цепочка подвергается так называемому DCT-преобразованию, являющемуся одной из разновидностей дискретного преобразования Фурье. Функцию преобразования в силу ее сложности для большинства наших читателей приводить здесь не будем, однако суть преобразования на словах поясним. Она заключается в том, что входную последовательность пикселов можно представить в виде суммы синусоидальных и косинусоидальных составляющих с кратными частотами (так называемых гармоник). В этом случае нам необходимо знать лишь амплитуды этих составляющих для того, чтобы восстановить входную последовательность с достаточной степенью точности. Чем большее количество гармонических составляющих нам известно, тем меньше будет расхождение между оригиналом и сжатым изображением. Большинство JPEG-кодеров позволяют регулировать степень сжатия. Достигается это очень простым путем: чем выше степень сжатия установлена, тем меньшим количеством гармоник будет представлен каждый 64-пиксельный блок.
Говоря техническим языком, JPEG-кодер представляет собой цифровой фильтр низких частот, причем чем выше степень сжатия, тем ниже частота среза этого фильтра. Визуально это проявляется в "сглаживании" изображения, потере контрастности, появлении "краевых эффектов" в виде "теней" возле резких границ. Поэтому степень сжатия и качество результата сильно зависят от характера изображения: если рисунок содержит много "штриховых" элементов, то он будет сжат хуже, чем "гладкое" изображение.
С целью анализа качества результатов были проведены следующие действия: *.jpg - файлы были преобразованы в BMP- формат, а затем была вычислена "разность" исходного изображения и картинки, прошедшей JPEG - кодирование.
Очевидно, что вторая картинка искажена гораздо сильнее первой. Оно и понятно - резкие, контрастные переходы содержат высокочастотные гармонические составляющие, которые JPEG просто "вырезает" при Фурье-преобразовании. Разностные картинки - это, конечно, хорошо, но хотелось бы иметь количественный критерий качества JPEG-преобразования.
Давайте попробуем сформулировать такой критерий. Как известно, каждый True-color пиксел может быть представлен тремя цветовыми составляющими: R, G и B, то есть каждый пиксел представляет собой вектор в трехмерном цветовом пространстве. Таким, образом, разницу между двумя пикселами можно найти как расстояние между двумя векторами в пространстве. Обозначим это расстояние как L. Тогда:
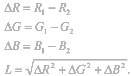
А разницу между двумя картинками можно найти как математическое ожидание расстояния между их соответствующими пикселами, то есть, говоря проще, как среднее арифметическое этих расстояний.
Конечно, можно предложить другой метод оценки качества кодирования, но и этот дает вполне наглядные результаты. Так, для рассмотренного выше примера Delta = 1.35 для "градиентной" картинки и 8.883 для "цветных прямоугольников" (естественно, чем больше Delta, тем хуже качество).
Однако приведенные выше примеры достаточно искусственны. Возьмем в качестве тестового примера фотографию реальных объектов. Исходный true-color файл имел размер 363 Кб. Попробуем сжимать эту картинку JPEG-кодером с различными коэффициентами сжатия. Сжатие производилось с помощью Corel Photo Paint.
Ниже по тексту под "степенью сжатия" понимается положение движка "Compression". Движок "Smoothing" во всех экспериментах находился в нулевом положении. В других программах коэффициент сжатия может быть выражен в других единицах и настройки могут быть победнее.
Итак, станем сжимать наш тестовый файл с различными коэффициентами и вычислять для каждого полученного результата нашу любимую величину Delta. Результат вполне закономерен: чем больше степень сжатия, тем больше вносимые искажения. При коэффициенте сжатия, равном 100, исходная картинка искажена очень сильно и, по сути, представляет собой набор блоков 8*8 с градиентной заливкой каждого из них.
Хорошо, а если мы возьмем файл со степенью сжатия, к примеру, 10, декодируем его в BMP формат и снова преобразуем его в JPEG с тем же коэффициентом сжатия? Останется ли картинка в том же качестве или будет дополнительно искажена кодером? Ответ на этот вопрос достаточно важен.
Каждый раз при открытии в графическом редакторе JPEG-файл преобразуется в некий внутренний формат редактора, в котором и происходят все операции с контентом файла. Когда вы сохраняете файл, он снова преобразуется из внутреннего представления редактора в JPEG-формат. Не лучше ли перед редактированием JPEG перевести его в какой-либо формат без потерь (например, в TIFF)? Пусть он занимает больше места на диске, зато за его содержимое можно будет не беспокоиться.
Чтобы прояснить этот вопрос, выполним ряд преобразований исходной картинки в JPEG и обратно (в BMP). При каждом преобразовании качество картинки немного падает (Delta растет). Самое первое преобразование дает наибольшее ухудшение качества, на фоне которого последующие искажения малозаметны. Для того чтобы сделать их более явными, найдем величины отклонений между самым первым JPEG-ом и картинкой после N преобразований BMP-JPEG.
Величины отклонений, непрерывно возрастая, асимптотически стремятся к какой-то определенной величине. Видно, что при каждом последующем преобразовании разница между текущей картинкой и предыдущей стремится к нулю с ростом количества преобразований BMP-JPEG, то есть картинка все более и более "сглаживается", приходит к "идеальному" для данного коэффициента виду.
Ну а если мы попытаемся "спасти" наше изображение, уменьшив его коэффициент сжатия? Качество картинки возрасти, конечно, не может - потери информации, увы, необратимы. Но, может быть, оно хотя бы не ухудшится?
Чтобы ответить на этот вопрос, выполним преобразование нашей многострадальной фотографии в JPEG с коэффициентом 50, после чего пересохраним ее с коэффициентом 10. Размер файла после первого преобразования составил 16 Кб, а после пересохранения с коэффициентом 10 - 30 Кб. При этом отклонение получившегося файла от предшествующего ему составило 1.98, то есть небольшое ухудшение качества все же наблюдается.
Итак, можем ли мы теперь ответить на вопрос, чем хорош и чем плох формат JPEG? Безусловно, его сильной стороной является большой коэффициент сжатия при сохранении исходной цветовой глубины. Именно это свойство обусловило его широкое применение в Internet, где уменьшение размера файлов имеет первостепенное значение, в мультимедийных энциклопедиях, где требуется хранение возможно большего количества графики в ограниченном объеме.
Отрицательным свойством этого формата является неустранимое никакими средствами, внутренне ему присущее ухудшение качества изображения. Именно этот печальный факт не позволяет применять его в полиграфии, где качество ставится во главу угла.
Однако формат JPEG не является пределом совершенства в стремлении уменьшить размер конечного файла. В последнее время ведутся интенсивные исследования в области так называемого вейвлет-преобразования (или всплеск-преобразования). Основанные на сложнейших математических принципах вейвлет-кодеры позволяют получить большее сжатие, чем JPEG, при меньших потерях информации. Несмотря на сложность математики вейвлет-преобразования, в программной реализации оно проще, чем JPEG. Хотя алгоритмы вейвлет-сжатия пока находятся в начальной стадии развития, им уготовано большое будущее.
Владимир Татарчевский
ComputerMan
Сайт о сжатии
>>
ARCTEST
>>
Сравнительные тесты
|
Альтернативные тесты
|
Графические тесты
|
Новости
|
Утилиты
|
Файл'менеджеры
|
Описания
|
Линки
|
Necromancer's DN
|
Поддержка
|
|
[an error occurred while processing this directive]