Ответы на упражнения:
-
Раздел 1. Методы сжатия без потерь
Ответы на упражнения к главе 3, "Словарные методы сжатия данных"
Упражнение: Предложите несколько более эффективных способов кодирования результатов работы LZ77, чем использование простых кодов фиксированной длины.
Можно указать два основных пути повышения эффективности кодирования:
- Использование предопределенных кодов переменной длины. Для кодирования длин совпадений и смещений часто используют универсальные коды целых чисел, например γ-коды Элиаса. Эффективность такого кодирования обеспечивается тем, что частоты длин совпадений и смещений в целом убывают с ростом значения числа, поэтому чаще всего используемые длины и смещения обычно будут получать коды меньшей длины. Часто имеет смысл изменять естественное отображение числа в код: например, если известно, что длина совпадения 2 используется в среднем реже длины совпадения 3, то длине 3 следует ставить в соответствие более короткий код, чем длине 2. Можно упорядочить длины совпадения в порядке убывания частоты использования при сжатии тестовых данных и кодировать не величину длины, а соответствующую позицию в ряду отсортированных чисел.
- Статистическое кодирование с помощью методов Хаффмана, Шеннона-Фано или арифметического кодирования. При этом кодирование может выполняться как исходя из безусловных частот элементов, так и условных. В последнем случае частота обычно обуславливается значением нескольких предыдущих элементов. При обработке смещений целесообразно кодировать на основе статистики только старшие биты чисел, поскольку, с одной стороны, вследствие большого количества возможных величин смещений статистика для отдельного значения накапливается медленно, с другой стороны, это позволяет избежать трудностей поддержания большого алфавита элементов, для которых подсчитывается статистика. Пример разбиения величин смещений на группы для организации кодирования такого рода приведен в табл. 3.7.
Упражнение: Из-за наличия порога THRESHOLD часть допустимых значений длины реально не используется, поэтому размер буфера BUF_SIZE может быть увеличен при неизменном LEN_LN. Проделайте соответствующие модификации фрагментов программ кодирования и декодирования.
Изменения выделены жирным шрифтом.
Кодирование:
const intTHRESHOLD = 2,
OFFS_LN = 14,
LEN_LN = 4;
const int
WIN_SIZE = (1 << OFFS_LN),
BUF_SIZE = (1 << LEN_LN) – 1 + THRESHOLD;
inline int MOD (int i) { return i & (WIN_SIZE-1); };
...
//собственно алгоритм сжатия
int buf_sz = BUF_SIZE;
/* инициализация: заполнение буфера, поиск совпадения
для первого шага
*/
...
while ( buf_sz ) {
if ( match_len > BUF_SIZE) match_len = BUF_SIZE;
if ( match_len < THRESHOLD ) {
CompressedFile.WriteBit (0);
CompressedFile.WriteBits (window [pos], 8);
match_len = 1;
}else{
CompressedFile.WriteBit (1);
CompressedFile.WriteBits (match_offs, OFFS_LN);
CompressedFile.WriteBits (match_len-THRESHOLD, LEN_LN);
}
for (int i = 0; i < match_len; i++) {
DeletePhrase ( MOD (pos+buf_sz) );
if ( (c = DataFile.ReadSymbol ()) == EOF)
buf_sz--;
else
window [MOD (pos+buf_sz)] = c;
pos = MOD (pos+1); // сдвиг окна на 1 символ
if (buf_sz)
AddPhrase (pos, &match_offs, &match_len)
;
}
}
CompressedFile.WriteBit (1);
CompressedFile.WriteBits (0, OFFS_LN);
Декодирование:
for (;;) {if ( !CompressedFile.ReadBit () ){
c = CompressedFile.ReadBits (8);
DataFile.WriteSymbol (c);
window [pos] = c;
pos = MOD (pos+1);
}else{
match_pos = CompressedFile.ReadBits (OFFS_LN);
if (!match_pos)
break;
match_len = CompressedFile.ReadBits (LEN_LN)+THRESHOLD;
for (int i = 0; i < match_len; i++) {
c = window [MOD (match_pos+i)];
DataFile.WriteSymbol (c);
window [pos] = c;
pos = MOD (pos+1);
}
}
}
Упражнение: Объясните, почему размеры полей, хранящих величины HLIT, HDIST и HCLEN, именно таковы, как это указано в табл. 3.10.
Размеры полей определяются диапазонами возможных значений числа литералов/длин совпадений, смещений и кодов длин кодов соответственно с учетом вычитаемых констант. Вообще, введение данных полей не было обязательным и ставило целью небольшое улучшение сжатия за счет уменьшения числа определяемых кодов. Величины констант объясняются следующим образом. Из HLIT вычитается 257, поскольку, с одной стороны, частота появления того или иного из 256 литералов обычно не зависит от величины литерала, и нет оснований надеяться, что литералы с большим значением не будут использоваться в сжимаемом блоке, и, с другой стороны, 257-ой по счету символ со значением 256 указывает на завершение блока и поэтому всегда используется. Вычитание из HDIST единицы предполагает, что должен иметься хотя бы один код смещения. Это условие исторически сложилось при развитии Deflate. Тем не менее, можно указать в таблице описания кодов смещений, что единственный код базы смещения имеет нулевую длину. Вычитание из HCLEN четверки позволяет записать количество кодов длин кодов посредством 4-битового слова, поскольку алфавит кодов длин кодов CWL может включать до 19 символов. При этом накладывается ограничение на минимальное количество описываемых кодов длин кодов — 4, поэтому коды 16, 17, 18, 0, располагающиеся в начале алфавита CWL, всегда определяются.
Упражнение: Объясните, почему использование ленивого сравнения при сжатии не требует внесения изменений в алгоритм декодера.
Ленивое сравнение представляет собой вариант стратегии разбора, ничем принципиально не отличающийся от “жадного” разбора. И в том, и в другом случае указатели всегда соответствуют полностью известной декодеру фразе. Декодирование указателей и литералов также всегда будет правильным инвариантно стратегии разбора, поскольку для декодера коды длин совпадений, смещений и литералов не зависят от частоты и последовательности появления соответствующих элементов. Декодер считывает уже готовые таблицы кодов. Таким образом, независимость алгоритма разжатия от деталей алгоритма разбора входной последовательности на фразы словаря и литералы определяется общей особенностью словарных схем типа LZ77 и блочно-адаптивным кодированием указателей и литералов.
Упражнение: Придумайте алгоритм кодирования найденной последовательности фраз и литералов.
Возможный алгоритм:
// меняем направление связей списка, с тем чтобы головным// элементом стал path[0]
i = MAX_T; int next_i = path[i].prev_t, next_prev = path[next_i].prev_t; while (i) { path[next_i].prev_t = i; i = next_i; next_i = next_prev; next_prev = path[next_i].prev_t; } path[MAX_T].prev_t = 0; // кодируем последовательность фраз и литералов do { if ((path[i].prev_t – i) == 1){ //кодируем литерал в позиции i encode_symbol (i); ... }else{ //кодируем строку, начинающуюся с позиции i, как // фразу со смещением path[i].offs и // длиной path[i].prev_t – i encode_phrase (i, path[i].offs, path[i].prev_t – i); ... } i = path[i].prev_t; } while (i);
Упражнение: Напишите упрощенный алгоритм декодирования.
Вариант решения:
metasymbol = decode_symbol (&symbol_type);if (symbol_type == LITERAL){
window [t+1] = metasymbol;
...
}else{
offset_base = metasymbol >> 3;
match_len = (metasymbol & 7) + 2;
if (match_len == 9)
match_length += decode_length_footer ()
;
offset_footer = decode_offset_footer ();
...
}
наверх
Ответы на упражнения к главе 4, "Методы контекстного моделирования"
Упражнение: Предложите способы увеличения средней скорости вычисления оценок для методов контекстного моделирования со смешиванием, как полным, так и частичным.
[незавершенный ответ]Сортировка счетчиков: в порядке убывания частоты; с учетом новизны, т.е. последние встреченные в контексте символы смещаются в начало списка (массива) счетчиков.
Предварительное суммирование счетчиков и организация многовходовой таблицы кумулятивных частот нередко обеспечивает значительное повышение скорости поиска. См. описание соответствующей структуры данных у Фенвика.
Продолжение следует...
Упражнение: Выполните действия, описанные в примере 2, используя ОВУ по методу C. Если текущий символ ‘б’, то точность его предсказания улучшится, останется неизменной или ухудшится?
В соответствии с табл. 4.4:
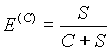 ,
,
поэтому при вычислении каждой оценки к общему числу просмотров контекста C следует прибавлять количество разных символов в контексте S, а не 1, как в методе A. Процесс вычисления оценки вероятности символа‘б’ можно описать в сравнении для методов A и C при помощи следующей таблицы:
|
Метод |
Последовательность оценок для КМ каждого порядка от 3 до –1 |
Общая оценка вероятности q(s) |
Представление требует битов |
||||
|
3 |
2 |
1 |
0 |
–1 |
|||
|
“ббв” |
“бв” |
“в” |
“” |
||||
|
A |
- |
|
|
- |
- |
|
2.6 |
|
C |
- |
|
|
- |
- |
|
4 |
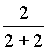
Обратите внимание, что в методе C формирование кодового пространства символа ухода производится без учета исключения, поэтому для контекста “в” оценка ‘б’ равна именно ![]() , а не
, а не 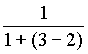 .
.
Таким образом, использование ОВУ по методу C приводит к ухудшению предсказания символа ‘б’ в указанной ситуации. Это, тем не менее, никоим образом не свидетельствует о преимуществе метода A над C. Действительно, если текущим символом является ‘г’, то он точнее предсказывается методом C, поскольку при этом оценка его вероятности выше:
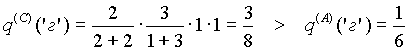 .
.
Метод C обычно позволяет точнее предсказывать уход из “молодых” контекстных моделей.
Упражнение: Добавление адаптивного метода ОВУ требует изменения действий по кодированию знака конца файла. Предложите вариант такой модификации.
Возможен такой вариант:
void encode (void){
...
// закодируем знак конца файла символом ухода с КМ(0)
int esc;
ContextModel *CM = &cm[context[0]];
calc_SEE (CM, &esc);
AC.encode (CM->TotFr, esc, CM->TotFr+esc);
CM = &cm[256];
calc_SEE (CM, &esc);
AC.encode (CM->TotFr, esc, CM->TotFr+esc);
AC.FinishEncode();
}
Кодирование знака конца файла можно осуществлять более элегантным способом, не выделяя данное действие как особый случай. Для необходимо либо явно ввести символ конца файла в алфавит, присвоив ему код 256, либо перейти от табличного хранения счетчиков символов контекста к списковому. В последнем случае функция encode может приобрести следующий вид:
void encode (void){
int c,success;
init_model ();
AC.StartEncode (CompressedFile.GetFile());
do{
c = DataFile.ReadSymbol();
// текст функции без изменения
...
}while (c != EOF);
AC.FinishEncode();
done_model ();
}
Упражнение: Объясните смысл слагаемого Fo–k,o в выражении (4.2).
Fo–k,o — это сумма всех “чистых” частот символов, т.е. это слагаемое равно сумме количеств реальных появлений символов в контекстах порядков o–k+1 … o без учета унаследованных частот и частот символа ухода. Можно сказать, что Fo–k,o характеризует собственную информационную значимость контекстов порядков o–k+1 … o — чем оно больше, тем весомее оценки, вычисляемые для данных контекстов. Коррекция знаменателя правой дроби в формуле (4.2) на величину Fo–k,o позволяет учесть то, что Fo–k,o символов, не равных si, были закодированы в контекстах порядка o–k+1 … o. Информация об этом отсутствует в родительской КМ (o–k).
Упражнение: Сравните DAFC с алгоритмом работы компрессора Dummy. Если пренебречь RLE, то какие изменения следует внести в Dummy, чтобы получить реализацию DAFC?
Введем константы и переменные:
const int N = 31; // число КМ(1)const int M = 50; // порог частоты встречаемости символа
int cnt[256], // частоты встречаемости символов
con_num; // количество КМ(1)
Изменим реализацию функции update_model:
void update_model (int c){while (SP) {
SP--;
if ((stack[SP]->TotFr + stack[SP]->esc) >= MAX_TotFr)
rescale (stack[SP])
;
// увеличение счетчика ухода не производится,
// счетчик символа ухода всегда равен 1
stack[SP]->count[c] += 1;
stack[SP]->TotFr += 1;
}
if ((++cnt[c] == M) && (con_num < N)) {
cm[c].esc = 1;
con_num++;
}
}
Модифицируем также функции encode_sym и decode_sym:
int encode_sym (ContextModel *CM, int c){if (CM->esc) stack [SP++].cm = CM;
...
}
int decode_sym (ContextModel *CM, int *c){
if (!CM->esc) return 0;
...
}
Упражнение: Сожмите строку с самого начала, найдите действительные значения fr(1) и fr(3), используемые при кодировании 'о' и 'л' в примере.
Для определенности будем считать, что алфавит строки равен {‘м’, ‘о’, ‘л’, ‘ч’, ‘н’, ‘е’, ‘_’, ‘к’}, и он определяет первоначальное ранжирование; начальные значения fr(i) примем за 1.
Процесс обработки опишем с помощью нижеприведенной таблицы.
|
Шаг |
Контекст |
Символ |
Счетчики символов в КМ и ранги |
Ранг i и частота его использования |
||||||||
|
м |
о |
л |
ч |
н |
е |
_ |
к |
i |
fr(i) |
|||
|
1 |
- |
м |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|||||
|
2 |
м |
о |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
2 |
1 |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|||||
|
3 |
о |
л |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
3 |
1 |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|||||
|
4 |
л |
о |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
2 |
2 |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|||||
|
5 |
о |
ч |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
4 |
1 |
|
2 |
3 |
1 |
4 |
5 |
6 |
7 |
8 |
|||||
|
6 |
ч |
н |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
5 |
1 |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|||||
|
7 |
н |
о |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
2 |
3 |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|||||
|
8 |
о |
е |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
6 |
1 |
|
3 |
4 |
2 |
1 |
5 |
6 |
7 |
8 |
|||||
|
9 |
е |
_ |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
7 |
1 |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|||||
|
10 |
_ |
м |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
2 |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|||||
|
11 |
м |
о |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
3 |
|
2 |
1 |
3 |
4 |
5 |
6 |
7 |
8 |
|||||
|
12 |
о |
л |
0 |
0 |
1 |
1 |
0 |
1 |
_ |
к |
3 |
2 |
|
4 |
5 |
3 |
2 |
6 |
1 |
7 |
8 |
|||||
наверх
Ответы на упражнения к главе 7, "Предварительная обработка данных"
Упражнение: Каким образом будет передан байт, равный самому флагу исключения?
Очевидно, что в случае коллизии на уровне самого флага исключения мы все равно можем воспользоваться этим флагом для передачи символа. В ходе обратного преобразования при чтении данных необходимо выполнять проверку:
//EXCLUSION_FLAG — флаг исключения...
c = DataFile.ReadSymbol();
if (c == EXCLUSION_FLAG){
c = PreprocFile.ReadSymbol();
// копировать символ в выходной файл без преобразования
DataFile.WriteSymbol(c);
}else{
// обработка символа;
// если требуется, то возможно обратное преобразование
...
}
Упражнение: Почему необходимо делать модификацию в том случае, когда предыдущий символ является пробелом?
Иначе преобразование может быть необратимым. Действительно, декодер не имеет информации, чтобы отличить добавленный в результате преобразования пробел от имевшегося изначально. Пример необратимого преобразования:
“очевидно,” --> “очевидно_,” ,
“очевидно_,” --> “очевидно_,” .