Ошибки и опечатки
Ниже приведены известные ошибки и неточности, а также опечатки, искажающие смысл текста.
| Страница | Исходный текст | Вариант правильного написания, пояснения | ||||||||||||||||
| Во всем тексте | "подраздел" следует понимать как "подпункт" %-) | |||||||||||||||||
| 18 | Если размер каждого такого файла в результате обработки уменьшается хотя бы на 1 бит, то 2n исходным файлам будет соответствовать самое большее 2n-1 различающихся архивных файлов. | Если размер каждого такого файла в результате обработки уменьшается хотя бы на 1 бит, то 2n исходным файлам будет соответствовать самое большее 2n-1 различающихся архивных файлов. | ||||||||||||||||
| 31 | Канонический алгоритм ХаффманаОдин из классических алгоритмов, известных с 60-х годов. |
Канонический алгоритм ХаффманаОдин из классических алгоритмов, известных с 50-х годов. | ||||||||||||||||
| 40, 41 | else if((li >= Third_qtr)&&(hi < First_qrt)){ | else if((li >= First_qtr)&&(hi < Third_qrt)){ | ||||||||||||||||
| 41 | На символ с меньшей вероятностью у нас тратится в целом большее число битов, чем на символ с меньшей вероятностью. | На символ с меньшей вероятностью у нас тратится в целом большее число битов, чем на символ с большей вероятностью. | ||||||||||||||||
| 45 |
// Если для хранения значений используется 31 бит, // каждый символ сдвинут на 1 байт вправо // в выходном потоке и при декодировании приходится // его считывать в 2 этапа. #define EXTRABITS ((CODEBITS-1)%8+1) |
// Если для хранения значений используется 31 бит, // каждый символ сдвинут на 1 бит вправо // в выходном потоке, и при декодировании приходится // его считывать в 2 этапа. #define EXTRABITS ((CODEBITS-1)%8+1) | ||||||||||||||||
| 46 |
void decode_normalize( void ) { while( range <= BOTTOM ) { range <<= 1; low = low<<8 | ((next_char<<EXTRABITS) & 0xFF); next_char = input_byte(); low |= next_char >> (8-EXTRABITS); range <<= 8; } } |
void decode_normalize( void ) { while( range <= BOTTOM ) { low = low<<8 | ((next_char<<EXTRABITS) & 0xFF); next_char = input_byte(); low |= next_char >> (8-EXTRABITS); range <<= 8; } } (убрана лишняя строка в цикле) | ||||||||||||||||
| 90, 91, 372 | Для обозначения метода Миллера-Уэгнама (Miller-Wegman) используется аббревиатура LZMV вместо LZMW | |||||||||||||||||
| 91 | Практические реализации LZMV неизвестны. | LZMW применяется в СУБД DB2 фирмы IBM для экономного представления информации непосредственно в реляционной базе данных. Для сжатия данных в СУБД более пригодны методы с явным словарем, что позволяет организовать статический режим сжатия с помощью заранее построенного словаря, без адаптации к локальным изменениям. «Жадная» стратегия построения словаря LZMW обеспечивает заметное преимущество над LZW по степени сжатия, поскольку данные обычно высокоизбыточны из-за наличия большого количества длинных повторяющихся строк и неоднородны (сжатие в DB2 осуществляется по строкам, а ведь отдельные колонки обычно сильно отличаются). Таким образом, LZMW имеет свою специфическую нишу. | ||||||||||||||||
| 179 | Описанные алгоритмы CTW работают с бинарным алфавитом. | Это не так. Существуют теоретические разработки и практические реализации мультиалфавитного CTW. Например, см. Sadakane K. et al. Implementing the Context Tree Weighting Method for Text Compression | ||||||||||||||||
| 189 | for( i=0; i<n; i++) { sum += count[i]; count[i] = sum - count[i]; } |
for( i=0; i<N; i++) { sum += count[i]; count[i] = sum - count[i]; } | ||||||||||||||||
| 190 | for( i=0; i<n; i++) { putc( in[pos], output ); pos = T[pos]; } |
for( i=0; i<n; i++) { pos = T[pos]; putc( in[pos], output ); } (поменять местами строчки) | ||||||||||||||||
| 199 | Рис. 5.15. 1-2-кодирование чисел:
|
| ||||||||||||||||
| 252 | Если индекс равен 58, то отображение будет таким: | Если индекс равен 56, то отображение будет таким: | ||||||||||||||||
| 271 | Требуемый объем памяти при сжатии. PPM: Варьируется в широких пределах, в зависимости от сложности моделирования и порядка модели; вырастает на малоизбыточных и очень неоднородных данных | Утверждение об увеличении расхода памяти в случае малоизбыточных данных спорно. Это зависит от используемых в компрессоре структур данных. В том случае, если в модели не хранится в явном виде информация о так называемых "виртуальных" состояниях, возникших только один раз, то ситуация может быть и обратной, особенно при большом порядке модели. В итоге для кодирования уже сжатого файла (степень сжатия около 1) может требоваться меньший объем памяти, чем для кодирования текстового файла (степень сжатия 3-4) такого же размера. | ||||||||||||||||
| 294 | Последовательность кодов для данного примера, попадающих в выходной поток: <256> <45> <55> <55> <151> <259>. | Не закодирован последний символ 55 и символ конца потока, поэтому: Последовательность кодов для данного примера, попадающих в выходной поток: <256> <45> <55> <55> <151> <259> <55> <257>. | ||||||||||||||||
| 297 | Упражнение. Составить алгоритм генерации таких цепочек. Попробовать сжать полученный таким образом файл стандартными архиваторами (zip, arj, gz). Если вы получите сжатие, значит, алгоритм генерации написан неправильно. | В общем случае это не так. Поскольку подразумеваются LZH-архиваторы, то может сказаться наличие кодирования по Хаффману. Если в сгенерированных данных есть локальные области преобладания одних символов над другими, то они могут быть сжаты LZH, пусть даже и блочно-адаптивным. | ||||||||||||||||
| 302 | Перепутаны подписи у рис. 1.1 и рис. 1.2. | |||||||||||||||||
| 307 | Неправильная матрица перехода RGB --> YCrCb: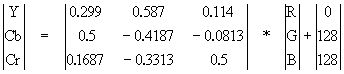 |
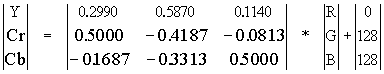 | ||||||||||||||||
| 308 | Плавное изменение цвета соответствует низкочастотной составляющей, а резкие скачки - низкочастотной. | Плавное изменение цвета соответствует низкочастотной составляющей, а резкие скачки - высокочастотной. | ||||||||||||||||
| 318 |
... } // Next range block Save_Coefficients_to_file(best); } // Next domain block |
... } // Next domain block Save_Coefficients_to_file(best); } // Next range block | ||||||||||||||||
| 318 |
Неверная формула сдвига по яркости: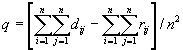
|
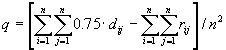
| ||||||||||||||||
| 318 |
Неверная формула меры: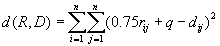
|
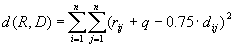
| ||||||||||||||||
| 318 |
Часть программы for (all domain blocks) for (all range blocks) + symmetry transformation |
Часть программы for (all range blocks) for (all domain blocks) + symmetry transformation | ||||||||||||||||
| 319 |
For(every pixel(i,j) in the block{ Rij = 0.75Dij + oR; } //Next pixel |
For(every pixel(i,j) in the block{ Rij = 0.75Dij + q; } //Next pixel | ||||||||||||||||
| 326 |
Перепутаны индексы у коэффициентов h в формулах преобразований: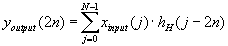 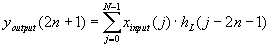
|
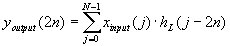 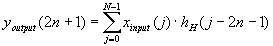
| ||||||||||||||||
| 327 |
Смещены индексы в формуле: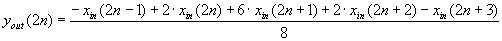
|
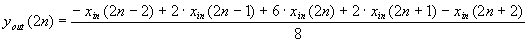
| ||||||||||||||||
наверх