М.А. Смирнов
Обзор применения методов безущербного сжатия данных в СУБД
Часть 1
Содержание | Часть 1 | Часть 2 | Часть 3 | Часть 4
Вопрос экономного кодирования информации в системах управления базами данных был поставлен в первой половине 1970-х годов [50, 3], но не потерял актуальности до сих пор. Многие современные исследователи отмечают недостаточную теоретическую проработку проблемы и неэффективность поддержки сжатия данных в промышленных СУБД [14, 24, 57].
Применение в СУБД экономного кодирования без потерь информации приводит к ряду положительных результатов. Наиболее очевидным эффектом является уменьшение физического размера базы данных, журнальных и архивных файлов. Но также часто достигается увеличение скорости выполнения запросов и снижение требований к объему оперативной памяти, что отмечается практически во всех работах в данной области знаний. Поэтому эффективная реализация поддержки сжатия данных существенно улучшает качество СУБД.
Интерес к задаче сжатия данных в СУБД изначально был обусловлен стремлением уменьшить физический объем баз данных. Цена подсистемы ввода-вывода составляла основную часть стоимости аппаратуры. Поэтому при надлежащем интегрировании в СУБД методов безущербного сжатия данных достигалась значительная экономия. Небольшое увеличение числа используемых тактов процессора для кодирования-декодирования более чем компенсировалось снижением затрат на подсистему ввода-вывода. Данный результат применения сжатия востребован и в настоящее время. Действительно, падение относительной стоимости устройств хранения информации на несколько порядков сопровождалось соответствующим увеличением размера типичных баз данных. Тем не менее, в настоящее время фокус интереса все больше смещается на увеличение производительности системы управления данными за счет использования сжатия.
Следует также отметить, что экономное кодирование способствует криптографической защите информации. Устранение статистической избыточности повышает криптостойкость алгоритмов закрытия информации и часто является предварительным действием в схемах шифрования данных.
Использование сжатия данных в СУБД связано с решением множества задач. Любая реализация экономного кодирования в СУБД связана с компромиссом между степенью сжатия, требуемым объемом оперативной памяти, числом обращений к внешней памяти и оперативной памяти, вычислительными затратами.
Для применения в СУБД требуются специфические методы и приемы экономного кодирования, поскольку обычные методы не удовлетворяют ряду требований. Практическая ценность реализации достигается только при обеспечении быстрого доступа к произвольной записи или элементу данных. Востребованы так называемые методы сжатия с сохранением упорядоченности, позволяющие выполнять операции сравнения без декодирования данных.
Проблема реализации сжатия в СУБД имеет также такие аспекты, как оптимизация выполнения запросов к сжатым данным, эффективное сжатие результатов выполнения запросов, экономное кодирование метаданных, оценка целесообразности сжатия отдельных элементов, выбор алгоритма сжатия и его параметров с учетом типовых запросов и характера данных.
Данный обзор состоит из двух разделов:
- рассмотрение состояния исследования проблемы сжатия данных в СУБД, главным образом реляционных;
- описание поддержки методов сжатия в ряде промышленных реляционных СУБД.
Затронута только проблематика использования методов сжатия без потерь информации. Это объясняется следующим. Во-первых, применение экономного кодирования без потерь информации является более универсальным решением, чем сжатие с потерями. Во-вторых, эта область точнее отвечает интересам автора. В-третьих, приемы сжатия данных с потерями информации (в первую очередь мультимедийных данных) и способы их использования в СУБД обладают существенной спецификой и требуют отдельного рассмотрения. Упомянуты лишь несколько подходов к сжатию данных реляционных таблиц с потерей информации.
Предпринята попытка систематически описать известные подходы к решению проблемы использования безущербного сжатия данных в СУБД, а также выявить недостаточно изученные и перспективные направления работ в проблемной области.
1. Исследования по применению методов сжатия в СУБД
На протяжении более двух десятков лет реляционные СУБД (РСУБД) подтвердили свою жизнеспособность и эффективность. Реляционные системы могут не без успеха заменять специализированные комплексы, например, системы управления многомерными базами данных. Подавляющий сегмент рынка СУБД занят РСУБД. Поэтому основная масса исследований и разработок, затрагивающих вопрос поддержки экономного кодирования в СУБД, явным или неявным образом ориентированы на реляционные системы (РСУБД). Но многие методы сжатия и сопутствующие приемы обработки запросов применимы к базам данных различного типа, например, многомерного и объектного. Исходя из вышеизложенного, данный обзор касается вопросов эффективной поддержки сжатия главным образом в РСУБД. Если излагаемые положения относятся к системам иного типа, это явно указывается.
Следующие несколько параграфов, вплоть до “Содержание и основные тенденции в исследованиях проблемы сжатия данных в СУБД”, являются вводными и содержат базовые положения таких областей знаний, как организация РСУБД и методы сжатия данных. Текст основной части обзора опирается на понятия и термины, введенные в этих параграфах.
Знаком ![]() показывается округление сверху, знаком
показывается округление сверху, знаком ![]() — округление снизу.
— округление снизу.
Запись ![]() означает, что число записано в системе счисления по основанию
означает, что число записано в системе счисления по основанию ![]() .
.
Базовые принципы устройства РСУБД. Терминология
Информация в реляционных базах данных (РБД) логически сохраняется в структурах табличного типа. Отдельная РБД может содержать несколько таблиц. Каждая таблица имеет определенное количество колонок (атрибутов, или столбцов). Отдельная строка таблицы как совокупность значений всех атрибутов однозначно определяется значением одной или нескольких колонок, составляющих так называемый первичный ключ. Например, первичным ключом таблицы, содержащей данные о людях и имеющей столбцы “Номер паспорта”, “Полное имя”, “Год рождения”, может быть колонка “Номер паспорта”.
Каждый атрибут имеет определенный тип и соответствующую ему область определения (domain). Атрибут принимает значения из области определения.
Некоторые столбцы могут не содержать определенных значений. Говорят, что такие атрибуты принимают неопределенные значения (отсутствующие, несуществующие). Эти квазизначения обычно обозначаются как NULL.
При описании структуры РБД в данном тексте используются как синонимы следующие термины:
- таблица, набор данных;
- строка, запись, кортеж1;
- колонка, атрибут, столбец, поле.
Физическая структура хранения РБД зависит от конкретной СУБД. Базе может соответствовать один или несколько файлов операционной системы. Аналогично, таблице может соответствовать один или несколько файлов. В случае так называемого горизонтального разбиения в разных файлах могут сохраняться строки таблицы, отличающиеся значениями некоторых столбцов. При вертикальном разбиении в отдельные файлы записываются группы колонок таблицы. Но практически во всех структурах можно выделить блоки фиксированного размера и регулярного устройства, образующие файлы БД. Вся хранимая информация укладывается в такие блоки. Блок содержит заголовок, собственно данные и является наименьшей порцией данных, пересылаемой при вводе-выводе данных в СУБД на уровне взаимодействия с файловой системой. Такой блок будет далее называться страницей.
Обычно в РБД используется построчный способ сохранения табличной информации. Тогда в одной странице может быть сохранено несколько строк. При этом каждая запоминаемая строка занимает определенное вакантное место (слот). В результате строка таблицы на физическом уровне может быть идентифицирована парой значений <идентификатор страницы, идентификатор слота>.
Для обеспечения эффективности операций ввода-вывода осуществляется буферизация страниц в оперативной памяти. При работе СУБД обычно используется несколько буферов. Совокупность буферов составляет так называемый буферный пул.
Средства обеспечения доступа к данным
В РБД широко используется такое средство логической группировки данных, как реляционное представление данных (view). Представление данных, или просто “представление”, — это виртуальная таблица, содержащая только описание данных (метаинформацию). Собственно данные размещаются в обычных таблицах. Представления в большинстве случаев применяются для облегчения разделения прав доступа и упрощения запросов. С функциональной точки зрения свойства представления, как правило, не отличаются от свойств таблицы.
Материализованное представление (materialized view, или snapshot) содержит не только метаинформацию, но и собственно данные в соответствии с состоянием исходных таблиц на момент создания или актуализации представления.
Для ускорения доступа к данным используется индексация данных. Индексные структуры содержат информацию, позволяющую по значению некоторого атрибута или атрибутов получить ссылки на строки таблицы, содержащие такие значения. Наиболее распространенными типами индексов являются B-деревья (B-tree) и битовые карты (bitmap) [2].
Среди РБД в настоящее время принято выделять два больших класса [2]:
- базы данных для оперативной обработки транзакций2 (ООТ) в реальном времени, обеспечивающие сохранение актуальных данных при работе информационных систем;
- хранилища данных (data warehouse), в которых накапливается в ретроспективе согласованная информация о некоторых процессах с целью дальнейшего ее использования в системах поддержки принятия решений (СППР).
Базы данных для ООТ отличаются высокой степенью нормализации данных, что в значительной степени уменьшает избыточность представления информации и облегчает поддержку согласованности. Как правило, промышленная БД такого типа содержит сотни и тысячи таблиц малого объема с небольшим количеством атрибутов и имеет сложную структуру.
Хранилища данных, организованные как РБД, обычно имеют простую денормализованную структуру, обеспечивающую высокую скорость выполнения сложных запросов, требующих агрегирования данных и вычисления сводных характеристик. Типовой схемой хранилища данных является так называемая “звезда” (star schema), при которой вся хранимая фактологическая информация записывается в одну большую таблицу фактов (fact table). Каждая строка таблицы фактов соответствует точке в многомерном пространстве, определяемом измерениями хранилища данных. Измерение классифицирует некоторый факт (обычно это число) и, как правило, имеет иерархическую структуру. Типичными измерениями являются время и территория. Для каждого измерения в таблице фактов заводится столбец, в котором в закодированном виде записываются значения измерения для каждой строки. С целью расшифровки закодированных значений для каждого измерения создается отдельная таблица (dimension table). Таблицы связываются на основании закодированных значений измерений так, что таблица фактов становится центром “звезды”, а таблицы измерений — ее лучами (см. Рис. 1). В общем случае хранилище данных имеет несколько таблиц фактов и, следовательно, состоит из нескольких “звезд”.
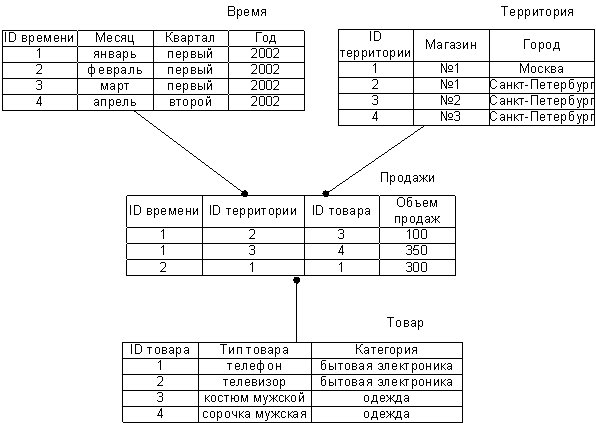
Рис. 1. Пример организации хранилища данных по схеме “звезда”
Стандартные тесты для сравнения СУБД
Наибольшее признание в качестве средств сравнительной оценки производительности транзакционных систем в настоящее время имеют тесты Совета по средствам обработки транзакций (Transaction Processing Council, TPC3). TPC является некоммерческим объединением, в которое входит большинство крупнейших производителей программного и аппаратного обеспечения для серверов СУБД.
Тесты TPC задают набор функциональных требований, которым должна удовлетворять любая транзакционная система вне зависимости от программного и аппаратного обеспечения. Каждый тест включает в себя БД определенного содержания и перечень запросов к ней.
В настоящее время определены следующие тесты TPC.
TPC-A и TPC-B являются устаревшими тестами для систем ООТ.
TPC-C представляет собой действующий тест для систем ООТ. В данном тесте имитируется работа системы учета поступления заказов. Производимые операции включают ввод и пересылку заказов, фиксирование платежей, проверку состояния выполнения заказов, мониторинг запасов товаров на складах. Операции отличаются сложностью и могут как требовать выполнения в реальном времени, так и образовывать очереди для последующего выполнения. Размер БД определяется выбранным коэффициентом масштабирования и равен не менее 80 Мбайт. Производительность измеряется в операциях по формированию заказа, производимых в минуту.
TPC-D является устаревшим тестом для СППР. Минимальный размер тестовой БД составляет порядка 1 Гбайт. TPC-D заменен на TPC-H и TPC/R.
TPC-H предназначен для тестирования СППР. Тест определяет набор специфических запросов к данным по розничной продаже и параллельно производимых модификаций данных. Структура используемых данных соответствует структуре в TPC-D. В зависимости от принятого коэффициента масштабирования размер БД может составлять от 1 до 10000 Гбайт. Производительность определяется по сводной характеристике, измеряемой в запросах в час.
TPC-R сходен с TPC-H, но позволяет производить дополнительную оптимизацию за счет априорного знания запросов.
TPC-W ориентирован на тестирование коммерческих систем с доступом через Web.
Необходимо также отметить тест Wisconsin, разработанный в начале 1980-х и имевший большую популярность в течение долгого времени. В первой половине 1990-х значительно устарел и отдал пальму первенства тестам TPC.
Основные методы сжатия данных. Терминология
Методы сжатия данных без потерь информации основаны на устранении избыточности представления информации. Экономное кодирование достигается за счет представления маловероятных событий более длинными словами, чем событий с высокой вероятностью наступления. Если вероятность наступления события равна ![]() , то, в соответствии с теоремой Шеннона о кодировании источника информации, такое событие выгоднее всего кодировать словом длиною
, то, в соответствии с теоремой Шеннона о кодировании источника информации, такое событие выгоднее всего кодировать словом длиною ![]() битов. Методы сжатия данных явно или неявно опираются на этот факт.
битов. Методы сжатия данных явно или неявно опираются на этот факт.
В результате процесса экономного кодирования единице исходных данных (символу, слову, строке, числу и т.п.) ставится в соответствие так называемое кодовое слово. Кодовое слово состоит из последовательности цифр, обычно двоичных. Совокупность всех кодовых слов образует код. Если длины всех кодовых слов одинаковые, то используемый код имеет фиксированную (постоянную) длину, иначе — переменную. Если исходные данные могут быть однозначно восстановлены по массиву соответствующих кодовых слов, то кодирование не приводит к потере информации, т.е. является безущербным, без потерь.
Эффективность сжатия как характеристика сокращения размера представления информации относительно исходного будет в данном обзоре определяться степенью сжатия. Степень сжатия принимается равной отношению объема исходных данных к объему соответствующих им сжатых данных и измеряется в разах.
Все методы сжатия принято разделять на два класса: методы статистического кодирования и методы словарного сжатия. В схемах сжатия также часто используются вспомогательные преобразования, обеспечивающие или способствующие выполнению этапа экономного кодирования.
Методы статистического кодирования явным образом опираются на теорему Шеннона. Такие методы включают в себя два этапа: оценка вероятности кодируемых элементов (моделирование) и собственно кодирование. На этапе кодирования выполняется замещение элемента ![]() с оценкой вероятности появления
с оценкой вероятности появления ![]() кодовым словом длиной
кодовым словом длиной ![]() битов. Этот этап иногда называется энтропийным кодированием. Оценки
битов. Этот этап иногда называется энтропийным кодированием. Оценки ![]() могут быть получены из безусловных частот встречаемости элементов, условных частот, т.е. с учетом контекста, более сложными способами. Восстановление данных без потерь обеспечивается в том случае, когда кодер и декодер оперируют одними и теми же оценками
могут быть получены из безусловных частот встречаемости элементов, условных частот, т.е. с учетом контекста, более сложными способами. Восстановление данных без потерь обеспечивается в том случае, когда кодер и декодер оперируют одними и теми же оценками ![]() в каждый момент времени.
в каждый момент времени.
Задача кодирования элемента с заданной вероятностью традиционно решается с помощью разновидностей метода Хаффмана и арифметического сжатия [1].
Алгоритм Хаффмана определяет процедуру построения кода переменной длины, средняя избыточность которого минимальна для всех неблочных кодов, т.е. задающих отображение ровно одного исходного элемента в одно кодовое слово. Поскольку слово может быть представлено только целым числом битов, при кодировании по Хаффману осуществляется приближение ![]() дробями, равными степеням двойки. Поэтому данный алгоритм неприменим непосредственным образом для экономного кодирования элементов бинарного алфавита. Код Хаффмана является префиксным и поэтому обычно представляется в виде дерева. Традиционно используется двухпроходная схема (статистический алгоритм Хаффмана): при первом просмотре данных подсчитывается статистика встречаемости элементов, т.е. строится модель данных, на основании которой формируется код; при втором просмотре данные сжимаются с помощью полученного кода. Оценки вероятности
дробями, равными степеням двойки. Поэтому данный алгоритм неприменим непосредственным образом для экономного кодирования элементов бинарного алфавита. Код Хаффмана является префиксным и поэтому обычно представляется в виде дерева. Традиционно используется двухпроходная схема (статистический алгоритм Хаффмана): при первом просмотре данных подсчитывается статистика встречаемости элементов, т.е. строится модель данных, на основании которой формируется код; при втором просмотре данные сжимаются с помощью полученного кода. Оценки вероятности ![]() при кодировании постоянны, и код не меняется. Известен адаптивный однопроходной вариант алгоритма, но он обладает существенно большей вычислительной сложностью и на практике не используется [23].
при кодировании постоянны, и код не меняется. Известен адаптивный однопроходной вариант алгоритма, но он обладает существенно большей вычислительной сложностью и на практике не используется [23].
Арифметическое сжатие, или арифметическое кодирование, позволяет при кодировании нескольких элементов представлять каждый элемент в среднем дробным числом битов. Поэтому обычно арифметическое сжатие обеспечивает бо́льшую степень сжатия, чем кодирование по Хаффману. Блок кодируемых элементов представляется дробью, определяемой произведением оценок вероятности ![]() всех элементов блока. Это и определило название метода. Чем
всех элементов блока. Это и определило название метода. Чем ![]() меньше, тем длиннее дробь, и больше требуется двоичных символов для ее представления. Алгоритм декодирования сложнее, чем для метода Хаффмана, но позволяет восстановить исходные данные без потерь. Арифметическое кодирование не требует явной перестройки кода при изменении оценок вероятности, поэтому обычно используется адаптивная однопроходная схема, позволяющая естественным образом учитывать локальные особенности данных.
меньше, тем длиннее дробь, и больше требуется двоичных символов для ее представления. Алгоритм декодирования сложнее, чем для метода Хаффмана, но позволяет восстановить исходные данные без потерь. Арифметическое кодирование не требует явной перестройки кода при изменении оценок вероятности, поэтому обычно используется адаптивная однопроходная схема, позволяющая естественным образом учитывать локальные особенности данных.
Идея словарного сжатия заключается в замене последовательностей элементов исходных данных на идентификаторы таких фраз некоторого словаря, которые совпадают с замещаемой последовательностью. Методы словарного сжатия эксплуатируют факт повторяемости строк символов. Словарь как совокупность фраз может строиться различным образом. Например, в него могут включаться такие строки, которые обладают наибольшей величиной характеристики ![]() , где
, где ![]() — частота встречаемости последовательности,
— частота встречаемости последовательности, ![]() — длина последовательности,
— длина последовательности, ![]() — длина идентификатора (указателя) фразы словаря.
— длина идентификатора (указателя) фразы словаря.
Среди словарных схем наибольшее распространении получили методы Зива-Лемпела. Словарные методы, относимые к этому классу, можно разделить на два семейства: LZ77 (LZ1) и LZ78 (LZ2). Схемы семейства LZ77 базируются на одноименном методе, предложенном в [62]. В методах данного семейства роль словаря играет порция уже обработанных данных. Последовательность обычно кодируется указанием позиции начала эквивалентной фразы в словаре (смещения) и длины совпадения. Пара <смещение, длина совпадения> в этом случае является указателем. Если кодируемый элемент отсутствует в словаре, то он некоторым образом помечается и представляется как есть. Такой элемент называется литералом. Из способа формирования словаря следует, что методы семейства LZ77 являются адаптивными.
На практике схемы типа LZ77 используются совместно с алгоритмами статистического кодирования указателей и литералов. Например, в методе LZH для экономного кодирования указателей и литералов используется алгоритм Хаффмана.
В схемах семейства LZ78 в словарь включаются не все последовательности, встреченные в обработанном массиве данных, а лишь “перспективные” с точки зрения вероятности появления в дальнейшем. Например, в методе LZ78 новая фраза формируется как сцепление (конкатенация) одной из фраз ![]() словаря, имеющей самое длинное совпадение с текущей кодируемой последовательностью
словаря, имеющей самое длинное совпадение с текущей кодируемой последовательностью ![]() , и символа
, и символа ![]() . Символ s является символом, следующим за последовательностью
. Символ s является символом, следующим за последовательностью ![]() [63]. В отличие от семейства LZ77, в словаре не может быть одинаковых фраз. В самом известном представителе семейства LZ78, методе LZW, словарь инициализируется фразами для всех символов алфавита кодируемых данных4. Указатели фраз кодируются словами фиксированной длины, определяемой размером словаря. В рамках метода семейства LZ78 несложно реализовать эффективное неадаптивное и полуадаптивное сжатие, при котором словарь строится заранее.
[63]. В отличие от семейства LZ77, в словаре не может быть одинаковых фраз. В самом известном представителе семейства LZ78, методе LZW, словарь инициализируется фразами для всех символов алфавита кодируемых данных4. Указатели фраз кодируются словами фиксированной длины, определяемой размером словаря. В рамках метода семейства LZ78 несложно реализовать эффективное неадаптивное и полуадаптивное сжатие, при котором словарь строится заранее.
Словарь, используемый в словарных методах сжатия, можно рассматривать как аналог статистической модели данных, применяемой в статистических методах.
Распространенным методом сжатия является кодирование длин серий (Run Length Encoding, RLE). Этот метод позволяет кодировать последовательности одинаковых элементов. Существует большое количество разновидностей кодирования длин серий. Например, последовательность идентичных элементов может представляться тройкой <флаг использования кодирования, длина серии, повторяемый элемент> [1].
Для кодирования целых чисел с неизвестным, но монотонно убывающим распределением вероятности используются так называемые универсальные коды. Избыточность универсальных кодов целых чисел для любого конкретного распределения и любого кодируемого числа ![]() является ограниченной сверху, если выполняется условие
является ограниченной сверху, если выполняется условие ![]() . Универсальными являются, например, коды Элайеса [1].
. Универсальными являются, например, коды Элайеса [1].
Преобразования, используемые в схемах сжатия данных
Сжатие данных может быть улучшено, если обрабатываются не исходные элементы, а их разности. Это характерно, например, для оцифрованных аналоговых сигналов, табличных данных. В последнем случае вычитаются не элементы, а последовательности элементов, т.е. строки таблицы. Для обеспечения возможности однозначного преобразования необходимо сохранить в первоначальном виде первый элемент или любой другой, служащий опорным (базовым). Описанный прием называется дифференциальным или разностным кодированием.
При наличии локальных группировок одинаковых символов сжатие может быть улучшено за счет предварительного преобразования “стопка книг”5. Все используемые элементы заносятся в список и кодируются своими номерами в нем. При каждом появлении элемента он переносится в голову списка, “сдвигая” вниз все остальные. В результате локально часто используемые элементы представляются одинаковыми числами, что позволяет применять простые методы сжатия.
Классификация методов по стратегиям обновления модели (словаря)
Схемы сжатия данных классифицируются также по способу построения и обновления модели (словаря). Выделяют четыре варианта моделирования:
- статическое (неадаптивное);
- полуадаптивное;
- адаптивное (динамическое);
- блочно-адаптивное.
При статическом моделировании для любых обрабатываемых данных используется одна и та же модель (словарь). Иначе говоря, не производится адаптация к особенностям сжимаемых данных.
Полуадаптивное сжатие предполагает, что для кодирования заданной последовательности выбирается или строится модель на основании анализа именно обрабатываемых данных.
Адаптивное моделирование является естественной противоположностью статической стратегии. По мере кодирования модель изменяется по заданному алгоритму после сжатия каждого элемента. Однозначность декодирования достигается тем, что, во-первых, изначально кодер и декодер имеют идентичную модель и, во-вторых, модификация модели при сжатии и разжатии осуществляется одинаковым образом.
В случае блочно-адаптивной стратегии обновление модели может выполняться после обработки целого блока элементов, в общем случае переменной длины.
Содержание и основные тенденции в исследованиях проблемы сжатия данных в СУБД
Как было ранее указано, интерес к вопросу сжатия данных в СУБД появился в первой половине 1970-х годов. Первые исследования решали задачи экономного кодирования в файловых системах управления данными. В 1980-х годах, в связи с активным внедрением РСУБД, публикации и разработки уже затрагивали вопросы экономного кодирования информации, хранимой в реляционных базах данных. Исследования 1990-x и последних нескольких лет включают в себя не только вопросы экономного представления собственно хранимых данных, но и сжатия служебной индексной информации, результатов выполнения запросов, эффективной оптимизации запросов с учетом сжатия данных. На Рис. 2 представлено распределение по годам публикаций, использованных при написании этого обзора и имеющих непосредственной отношение к проблеме использования экономного кодирования в СУБД. На Рис. 3 приведено аналогичное распределение, но отдельно показаны публикации, освещающие вопросы сжатия собственно данных и вопросы экономного кодирования индексов6.
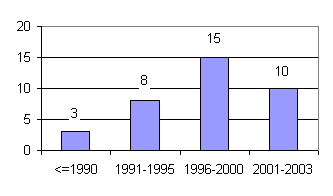
Рис. 2. Распределение публикаций по годам
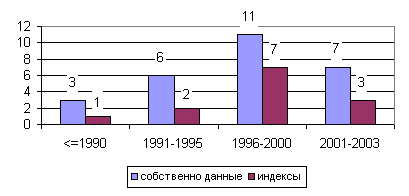
Рис. 3. Распределение публикаций по годам с учетом охватываемой темы: сжатие собственно данных и сжатие индексных структур
Одновременно с изменением направленности и количества исследований смещался и фокус интереса к сжатию. В связи с удешевлением устройств памяти все больший интерес проявляется к такому возможному эффекту, как ускорение обработки запросов при использовании сжатия.
Повышение производительности за счет уменьшения размера хранимых данных обусловлено следующими эффектами [32, 14, 28]:
- уменьшается среднее время поиска и доступа к информации в устройствах внешней памяти, поскольку для хранения данных требуется меньший объем носителя;
- повышается фактическая пропускная способность канала ввода-вывода устройства внешней памяти, так как информация о большем количестве записей передается за одну операцию, и снижается количество вспомогательных операций инициации и прекращения обмена;
- аналогично, повышается фактическая пропускная способность вычислительной сети, что актуально для распределенных баз данных и систем клиент-сервер;
- уменьшается объем выводимой информации на устройства журналирования, поскольку записи собственно данных и журнальные записи становятся короче;
- увеличивается фактический размер буфера устройства внешней памяти, и повышается процент успешных попаданий в него;
- аналогично, увеличивается фактический размер буферного пула СУБД, что позволяет достичь лучшего коэффициента успешных попаданий при неизменном физическом размере буфера или такого же коэффициента при меньшем размере.
Таким образом, повышение быстроты выполнения запросов вследствие использования сжатия вызвано:
- увеличением пропускной способности каналов связи;
- уменьшением времени ожидания извлечения данных из внешней и оперативной памяти за счет того, что больше информации помещается в буфер устройств внешней памяти, оперативную и сверхоперативную (кеш) память.
Использование сжатия данных в СУБД связано с решением множества задач:
- выбор метода сжатия и уровня сжимаемого блока данных в иерархии физической структуры базы данных, т.е. выбор гранулярности блока, сжатие которого осуществляется независимо от других данных; произвольный доступ к данным поддерживается с точностью до такого блока;
- выбор между аппаратным и программным сжатием;
- выбор местоположения модуля сжатия в общей архитектуре вычислительной системы;
- обеспечение обновления данных и выполнения запросов к сжатым данным.
Применение сжатия связано с рядом отрицательных эффектов:
- увеличение расходов вычислительных ресурсов и, возможно, оперативной памяти;
- переменная длина записей требует существенного усложнения программного обеспечения;
- нарушение характеристик данных (например, лексикографической упорядоченности, что требует использования методов сжатия, сохраняющих порядок сортировки);
- уменьшение возможности успешного восстановления после ошибок.
Для применения в СУБД требуются специфические методы и приемы экономного кодирования, поскольку обычные методы [14]:
- не обеспечивают требуемой скорости декодирования;
- работают с блоками достаточно большого объема и не поддерживают произвольный доступ, что не позволяет использовать индексы, в то время как во многих приложениях часто требуется быстрый произвольный доступ (системы ООТ);
- не учитывают структуру данных; в БД часто сильны вертикальные зависимости между значениями таблицы и слабы горизонтальные; для разных колонок могут быть более подходящими разные методы сжатия;
- не учитывают статистику по данным, накапливаемую СУБД для последующей оптимизации запросов.
Очень полезным свойством метода сжатия может быть сохранение упорядоченности, что позволяет оперировать при выполнении запросов непосредственно закодированными данными. Если порядок сортировки закодированных данных соответствует порядку исходных, то можно выполнять операции неэквивалентного сравнения над сжатыми данными (меньше, больше, строгие неравенства). Многие обычные методы сжатия не обладают такой особенностью.
Во многих теоретических исследованиях и практических разработках не уделяется должного внимания целому ряду аспектов проблемы сжатия данных в СУБД. В частности, в [14] указываются следующие вопросы, требующие изучения.
- Эффективное сжатие текстовых данных. В некоторых работах для сжатия строк используются простые техники типа устранения неопределенных значений или кодирования строковых атрибутов с помощью словаря, содержащего все различные значения атрибута [57]. Но часто неопределенных значений мало, а различающихся значений атрибута много. В других работах используются LZ-методы. В SYBASE IQ используется словарный метод типа LZH для сжатия страницы [25, 56]. В DB2 реализована модификация другого словарного метода, LZW, для сжатия строки [32, 10]. Быстродействие в этих системах страдает от дополнительных издержек на декодирование сжатых строк и атрибутов, не требующихся для выполнения запроса. Техники сжатия, не позволяющие декодировать отдельные строки, требуют сохранения в памяти всей разжатой страницы, что приводит к непрактичному использованию буферного пула. Поэтому необходимо развивать методы сжатия строковых атрибутов.
- Использование сжатия должны подстраиваться под запросы. Например, не следует сжимать те столбцы, по которым часто выполняется соединение.
- Результирующее сжатие. Практически не уделяется внимание задаче экономного кодирования результата выполнения запроса. Но это актуально при передаче данных клиенту в случае малой пропускной способности канала связи и строгих ограничениях на объем памяти компьютера-клиента.
- Оптимизация запросов в СУБД со сжатием. Оптимизация запросов является ключевой проблемой для СУБД со сжатием данным, поскольку эффективность главным образом зависит от того, когда выполняется декодирование при обработке запроса. Мало работ затрагивает эту проблему. Можно указать только [14, 4, 57].
Содержание | Часть 1 | Часть 2 | Часть 3 | Часть 4
Подстрочные примечания
1 Кортеж (tuple) — группа взаимосвязанных элементов данных. Термин реляционной алгебры.2 От английского On-Line Transaction Processing, или OLTP.
3 http://www.tpc.org/
4 Welch T.A. A technique for high-performance data compression. IEEE Computer 17(6):8-19, Jun. 1984.
5 Рябко Б.Я. Сжатие данных с помощью стопки книг // Проблемы передачи информации. 1980. Т.16. №4. С. 16-21.
6 Одна публикация учитывалась два раза, если удовлетворяла двум критериям одновременно.
